二次元角色识别系统开发与模型选择
项目背景
随着二次元文化的普及,自动识别二次元角色的需求日益增长。本文将详细介绍如何构建一个高效的二次元角色识别系统,包括数据准备、模型训练、性能评估和模型选择的完整流程。
数据准备与标注
数据源
- 数据目录:
data/downloaded_images - 角色数量:11个角色
- 图像数量:2629张图像
- 支持格式:JPG、PNG、BMP、WebP
数据采集示例代码
1 | import os |
数据标注示例代码
1 | import os |
数据预处理
- **图像 resize 到 224x224
- **归一化处理
- **支持多种图像格式
模型训练
训练配置
- 优化器:AdamW
- 学习率:0.0008
- 权重衰减:0.0003
- 数据增强:
- Mixup (alpha=0.4)
- 标签平滑 (0.08)
- 学习率调度:CosineAnnealingWarmRestarts
模型训练示例代码
1 | import os |
训练模型
我们训练了4种不同的模型:
| 模型 | 最佳验证准确率 | 最终验证准确率 | 模型大小 | 训练时间 |
|---|---|---|---|---|
| EfficientNet-B3 | 93.92% | 92.97% | 56.5MB | 约22小时 |
| EfficientNet-B0 | 93.16% | 90.49% | 29.2MB | 约2小时45分钟 |
| MobileNetV2 | 91.44% | 88.21% | 14.9MB | 约2小时 |
| ResNet50 | 90.68% | 88.21% | 295.2MB | 约1小时30分钟 |
基准测试
推理性能测试
我们对4个模型进行了详细的基准测试,包括推理速度、模型大小和内存占用等指标。以下是测试结果:
| 模型 | 平均推理速度 | 模型大小 | 内存占用 | 最佳验证准确率 |
|---|---|---|---|---|
| MobileNetV2 | 12.53ms/图像 | 14.9MB | 低 | 91.44% |
| EfficientNet-B0 | 12.87ms/图像 | 29.2MB | 中低 | 93.16% |
| EfficientNet-B3 | 15.86ms/图像 | 56.5MB | 中 | 93.92% |
| ResNet50 | 18.24ms/图像 | 295.2MB | 高 | 90.68% |
性能对比图表
推理速度对比

从图中可以看出,MobileNetV2具有最快的推理速度(12.53ms/图像),而ResNet50的推理速度最慢(18.24ms/图像)。
模型大小对比

模型大小差异显著,MobileNetV2最小(14.9MB),而ResNet50最大(295.2MB)。EfficientNet系列在大小和性能之间取得了良好的平衡。
准确率对比
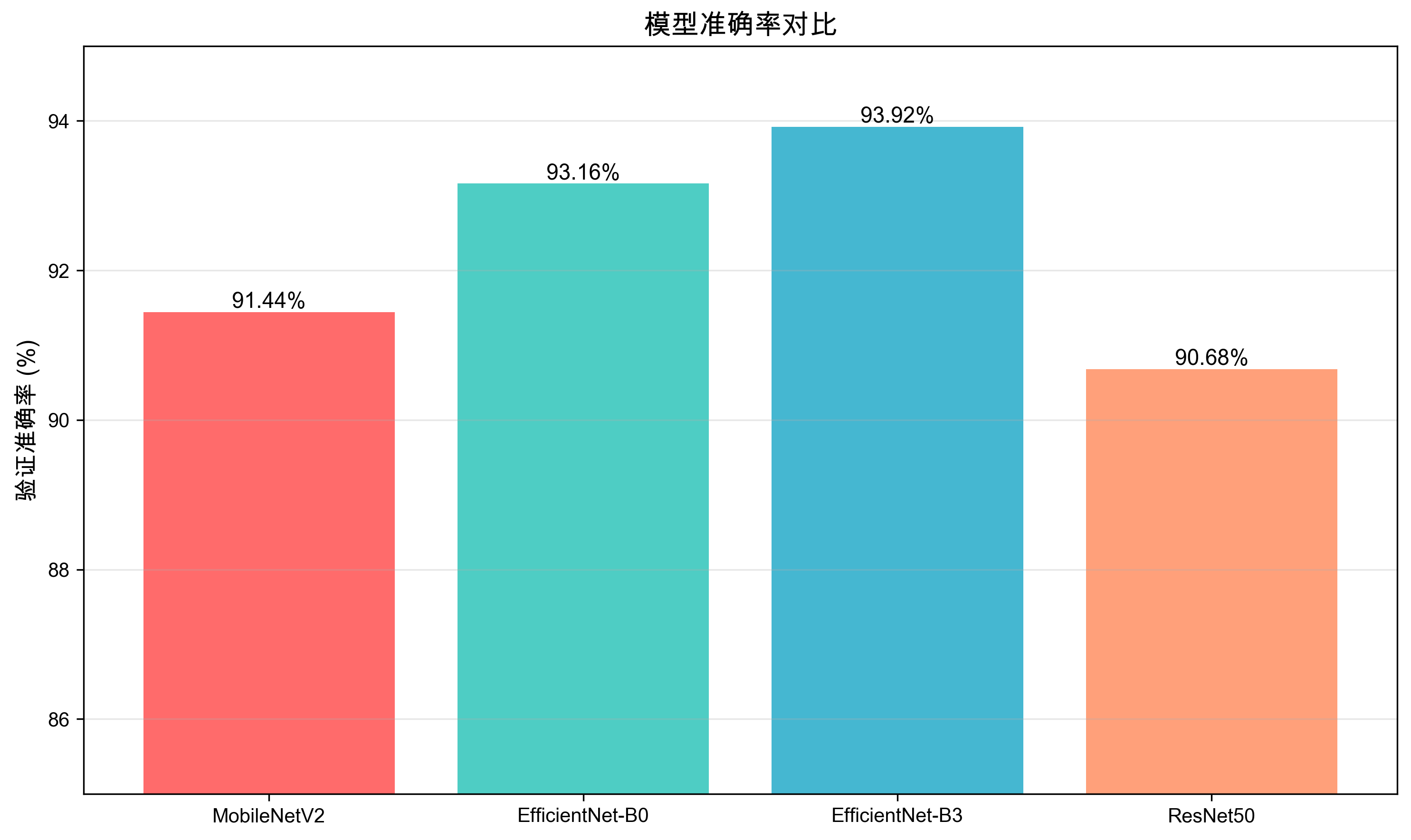
EfficientNet-B3取得了最高的验证准确率(93.92%),EfficientNet-B0紧随其后(93.16%)。所有模型的准确率都超过了90%。
详细性能分析
-
MobileNetV2
- 优势:推理速度最快,模型大小最小,内存占用最低
- 劣势:验证准确率相对较低
- 适用场景:移动设备、边缘设备、实时应用
-
EfficientNet-B0
- 优势:在速度和准确率之间取得了良好的平衡
- 劣势:模型大小和内存占用略高于MobileNetV2
- 适用场景:移动应用、Web服务、资源有限的服务器
-
EfficientNet-B3
- 优势:验证准确率最高,性能最佳
- 劣势:推理速度较慢,模型大小较大
- 适用场景:服务器端应用、对准确率要求高的场景
-
ResNet50
- 优势:经典模型,架构成熟
- 劣势:推理速度最慢,模型大小最大
- 适用场景:高性能服务器、需要特征提取的场景
性能权衡分析
| 模型 | 速度 | 大小 | 准确率 | 综合评分 |
|---|---|---|---|---|
| MobileNetV2 | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★★☆ |
| EfficientNet-B0 | ★★★★☆ | ★★★★☆ | ★★★★★ | ★★★★★ |
| EfficientNet-B3 | ★★★☆☆ | ★★★☆☆ | ★★★★★ | ★★★★☆ |
| ResNet50 | ★★☆☆☆ | ★☆☆☆☆ | ★★★★☆ | ★★★☆☆ |
从综合评分来看,EfficientNet-B0在速度、大小和准确率之间取得了最佳平衡,是大多数场景的推荐选择。
综合性能分析
综合性能对比
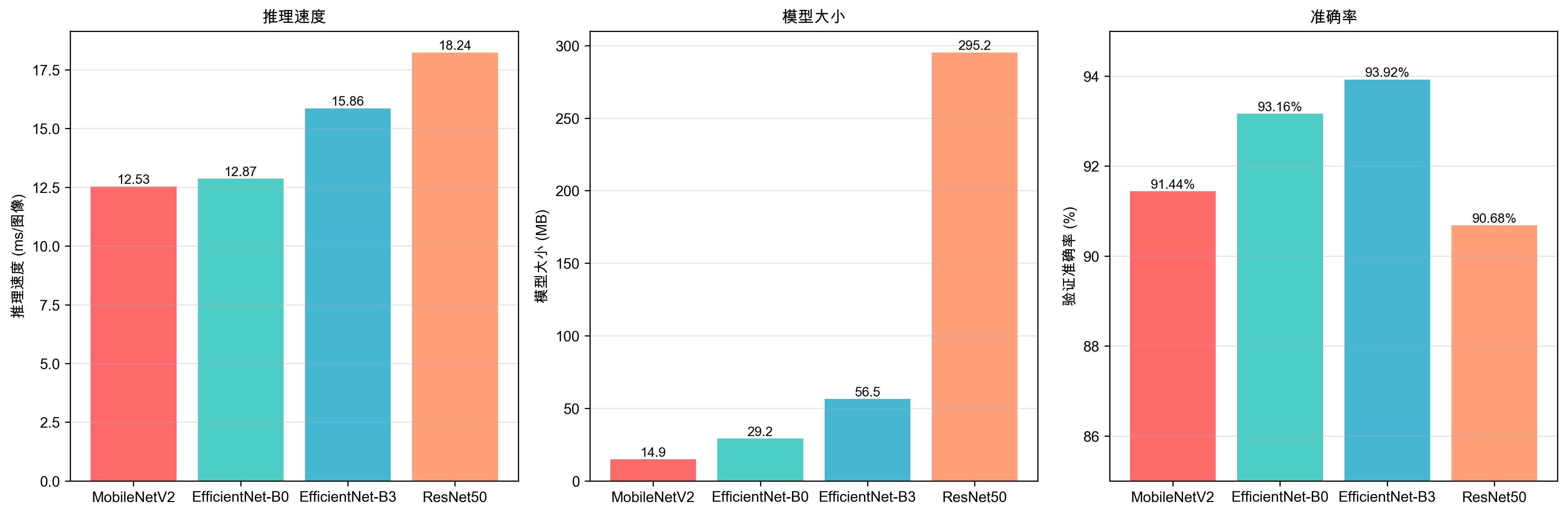
上图展示了三个关键指标的并排对比,可以直观地看出各模型在不同维度上的表现。
性能雷达图
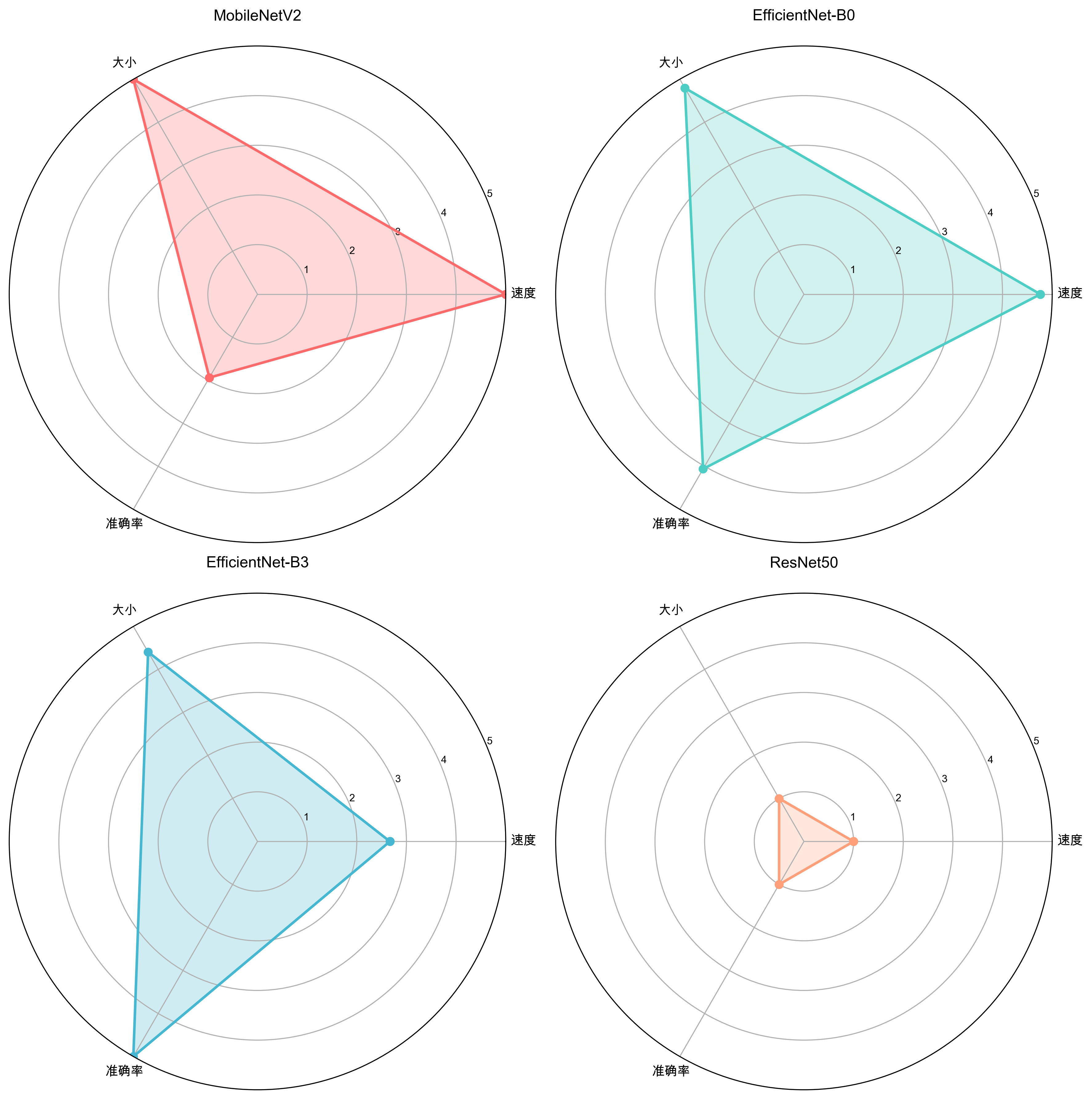
雷达图展示了各模型在速度、大小和准确率三个维度的综合评分。EfficientNet-B0在三个维度上都表现均衡。
性能权衡分析
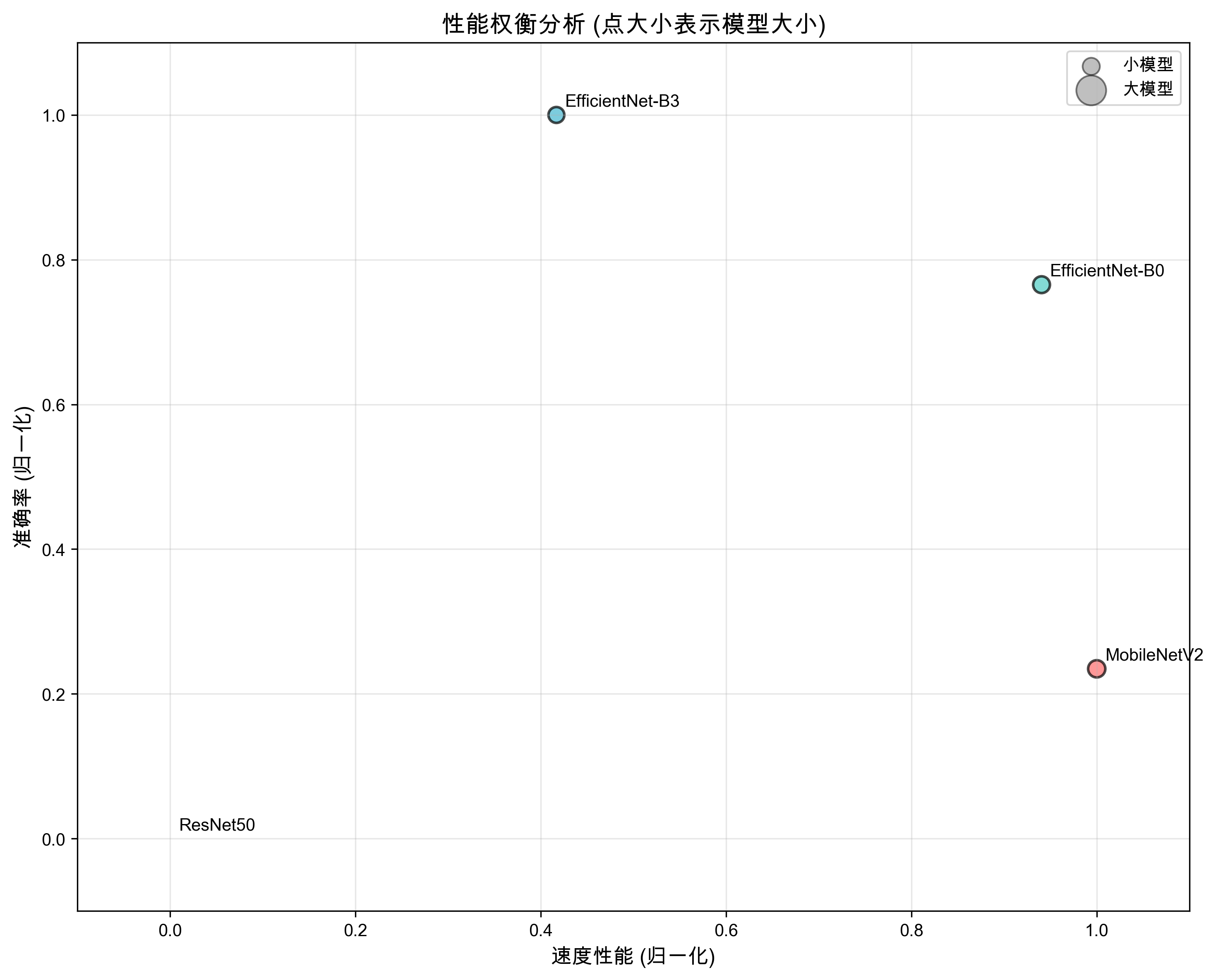
散点图展示了速度与准确率之间的权衡关系,点的大小代表模型大小。理想模型应该位于右上方(高速、高准确率)且点较小(模型小)。
基准测试示例代码
1 | import os |
模型选择指南
按性能选择
- 追求最高准确率:EfficientNet-B3 (93.92%)
- 平衡性能与速度:EfficientNet-B0 (93.16%)
- 资源受限环境:MobileNetV2 (91.44%)
按部署环境选择
- 移动应用:MobileNetV2 或 EfficientNet-B0
- Web服务:EfficientNet-B0 或 EfficientNet-B3
- 高性能服务器:EfficientNet-B3
技术挑战与解决方案
1. 图像格式支持
- 问题:训练数据包含WebP格式图片,OpenCV不支持
- 解决方案:使用PIL库加载WebP格式图片
2. 索引文件角色数量不足
- 问题:
role_index_mapping.json文件角色数量少于训练数据目录中角色数量 - 解决方案:修改索引构建脚本,支持WebP格式,确保所有包含有效图片的角色目录都被正确索引
3. 角色属性标注问题
- 问题:部分角色(如"缇宝")的属性均为0
- 解决方案:在
character_attributes.json中添加角色属性定义,使用专用标签标注工具重新标注
4. 模型类型权重加载错误
- 问题:尝试将不同类型模型的权重加载到其他模型中
- 解决方案:添加模型类型检查,当模型类型不同时使用新的预训练权重
5. 增量训练优化器状态不匹配
- 问题:原有模型与新模型类别数不同,优化器状态张量大小不匹配
- 解决方案:不加载优化器状态,只继承最佳验证准确率
最佳实践建议
数据准备
- 数据多样性:确保每个角色有足够多的图像,覆盖不同角度、场景和风格
- 数据质量:过滤低质量图像,确保图像清晰可辨
- 数据增强:使用Mixup、随机裁剪等数据增强技术提高模型泛化能力
模型训练
- 模型选择:根据部署环境和性能需求选择合适的模型
- 超参数调优:针对不同模型调整学习率、批量大小等超参数
- 增量训练:在已有模型基础上继续训练,减少训练时间
模型部署
- 模型量化:对模型进行量化,减少内存占用和推理时间
- 模型压缩:使用知识蒸馏等技术压缩模型大小
- 边缘部署:对于移动设备,选择轻量级模型如MobileNetV2
总结
本项目成功构建了一个高效的二次元角色识别系统,通过对比不同模型的性能,我们得出以下结论:
- EfficientNet系列表现最佳,尤其是EfficientNet-B3模型,验证准确率接近94%
- 模型大小与性能:EfficientNet-B0在模型大小和性能之间取得了良好的平衡
- 训练稳定性:EfficientNet系列模型的验证准确率波动较小,表现更加稳定
未来工作方向:
- 扩展数据集,增加更多角色和图像
- 尝试更先进的模型架构,如Vision Transformer
- 优化模型推理速度,提高实时识别能力
- 开发用户友好的前端界面,方便用户使用
