模型简介
YOLO 是一种实时目标检测算法家族的名称。与传统的需要先进行区域提议(Region Proposal)再进行分类的两阶段检测器(如 Faster R-CNN)不同,YOLO 将目标检测视为一个回归问题,直接从整个图像中预测边界框的位置和类别概率,实现了端到端(end-to-end)的检测。
- 核心思想:
- 网格划分: 将输入图像划分为 S x S 的网格 (Grid Cells)。
- 单元格负责制: 如果一个物体的中心落入某个网格单元,则该单元负责检测该物体。
- 边界框预测: 每个网格单元预测 B 个边界框 (Bounding Boxes) 以及这些框的置信度 (Confidence Score,表示框内含有物体的概率及框的准确度)。每个边界框包含 5 个预测值:
x,y(框中心相对单元格的坐标),w,h(框宽高相对整张图像的比例), 和confidence。 - 类别概率预测: 每个网格单元还预测 C 个条件类别概率 (Conditional Class Probabilities),即在包含物体的前提下,该物体属于每个类别的概率。
- 最终检测: 将每个边界框的置信度与对应单元格的类别概率相乘,得到每个框针对每个类别的得分。通过设置阈值过滤低分框,并使用非极大值抑制 (Non-Maximum Suppression, NMS) 消除冗余的重叠框,得到最终的检测结果。
CVAT简介
基于 Web 的、功能强大的计算机视觉数据标注工具。它支持对图像和视频进行多种类型的标注,是计算机视觉项目(尤其是监督学习)中数据准备阶段的重要工具
- 主要功能:
- 多种标注类型:
- 边界框 (Bounding Boxes): 用于目标检测任务,框出物体的位置。
- 多边形 (Polygons): 用于实例分割任务,精确勾勒物体的轮廓。
- 关键点 (Points / Skeleton): 用于姿态估计、人脸关键点检测等任务。
- 分割掩码 (Segmentation Masks): 用于语义分割任务,为图像中的每个像素分配类别。
- 标签 (Tags): 用于图像分类任务,为整个图像分配类别标签。
- 轨迹/立方体 (Tracks/Cuboids): 支持视频标注,可以跟踪物体或标注3D边界框。
- 图像和视频支持: 可以直接对单张图片或整个视频序列进行标注。视频标注支持插值(interpolation),可以减少手动标注的工作量。
- 半自动和自动标注: 集成了多种 AI 模型(如目标检测、分割模型,包括 YOLO、SAM 等),可以预标注数据,然后由人工进行修正,提高效率。支持连接外部 AI 模型(如通过 Nuclio)。
- 协作: 支持多用户协作,可以分配任务、进行审核等。
- 数据管理: 提供项目 (Project) 和任务 (Task) 管理功能,方便组织数据。
- 多种导出格式: 支持导出为多种常见的数据集格式,如 COCO JSON, Pascal VOC XML, YOLO, MOT, Segmentation Mask 等,方便与各种深度学习框架对接。
- 可扩展性: 开源,可以通过插件或集成自定义工具进行扩展。
- 部署: 可以通过 Docker 在本地、服务器或云上部署。
- 多种标注类型:
CVAT标注结果导出
使用从 CVAT 导出的 YOLO 格式数据,并在 CPU 上训练一个新的 YOLOv8 模型(使用 Ultralytics 框架),以下详细步骤。
重要提示: 在 CPU 上训练目标检测模型(尤其是像 YOLOv8 这样较现代的模型)将会非常非常慢。根据你的数据集大小、模型大小和 CPU 性能,一个 epoch 可能需要数小时甚至更长时间。这通常只适用于非常小的数据集、快速原型验证或没有 GPU 可用的情况。请有心理准备。
步骤 1:从 CVAT 导出 YOLO 格式数据
- 登录 CVAT 并导航到你已完成标注的任务 (Task)。
- 点击任务卡片上的 “Actions” (或任务页面内的菜单按钮)。
- 选择 “Export task dataset”。
- 在弹出的窗口中:
- 选择格式: 务必选择
YOLO或YOLO ZIP。 - 子集划分 (可选但推荐): 如果你在 CVAT 中已将数据分配到
Train,Validation,Test子集,请确保勾选了相应的选项来导出这些子集。这会省去你手动划分的步骤。如果没划分,则导出整个数据集。 - 保存图像: 确保勾选了 “Save images” 选项。
- 选择格式: 务必选择
- 点击 “OK” 或 “Export”。
- 等待导出任务完成,然后下载生成的 ZIP 文件。
步骤 2:准备数据集文件
- 解压 ZIP 文件: 将下载的 ZIP 文件解压到你电脑上一个方便访问的位置,例如
~/datasets/my_yolo_dataset。 - 检查文件结构: 解压后,检查里面的内容。一个典型的 YOLO 导出(特别是包含子集划分的)可能包含:
data.yaml(或obj.data和obj.names文件):这是配置文件,非常重要。train/(或类似的名称)images/: 包含训练集的图像文件 (.jpg,.png等)。labels/: 包含训练集的标注文件 (.txt),每个图像对应一个。
valid/(或val/)images/: 包含验证集的图像文件。labels/: 包含验证集的标注文件。
test/(可选)images/: 包含测试集的图像文件。labels/: 包含测试集的标注文件。
- 如果导出时没有划分: 你可能只有一个
images/和一个labels/文件夹,以及配置文件。
- 验证/修改
data.yaml(或创建它): 这是告诉 YOLOv8 框架如何找到你的数据的关键文件。- 如果已有
data.yaml: 用文本编辑器打开它。它看起来类似这样:你需要仔细检查并可能修改:1
2
3
4
5
6
7
8path: ../datasets/my_yolo_dataset # !!可能需要修改:数据集根目录的相对或绝对路径
train: train/images # !!训练集图片路径 (相对于 path)
val: valid/images # !!验证集图片路径 (相对于 path)
# test: test/images # 可选:测试集图片路径
# Classes
nc: 9 # !!类别数量,必须准确
names: ['bus', 'car', 'clock', ...] # !!类别名称列表,顺序必须与 labels/*.txt 中的类别ID (0, 1, 2...) 完全对应!path: 确保它正确指向你解压数据集的根目录。相对于你将要运行训练命令的位置。使用绝对路径通常更安全。例如:/home/your_user/datasets/my_yolo_dataset。train,val,test: 确保它们正确指向包含图像文件的文件夹(相对于path定义的路径)。nc: 确保类别数量正确无误。names: 极其重要! 确保这个列表中的类别名称顺序与 CVAT 导出时使用的类别 ID(从 0 开始)以及labels/文件夹下.txt文件中使用的数字 ID 完全一致。CVAT 导出 YOLO 格式时通常会保证这一点,但务必检查。
- 如果只有
obj.data和obj.names: 你需要手动创建一个data.yaml文件。- 打开
obj.names,将里面的类别名称按顺序列入data.yaml的names字段。计算类别数量填入nc。 - 打开
obj.data,它通常包含类别数量、训练集/验证集图像列表文件的路径等信息。你需要根据这些信息和你的实际文件结构来填写data.yaml中的path,train,val字段。你可能需要将obj.data中指向的图像列表文件(例如train.txt,valid.txt)也放到你的数据集目录中,或者直接修改data.yaml指向包含图像的文件夹。创建data.yaml通常更符合现代 YOLOv8 的习惯。
- 打开
- 如果已有
- 手动划分数据集 (如果导出时未划分):
- 如果你只有一个
images/和labels/文件夹,你需要手动将其划分为训练集和验证集。 - 创建子目录:在数据集根目录下创建
train/images,train/labels,valid/images,valid/labels。 - 编写脚本或手动移动文件:
- 确定划分比例(例如,80% 训练,20% 验证)。
- 遍历
images/文件夹中的所有图像文件。 - 对于每个图像文件(例如
image1.jpg),找到其对应的标注文件(labels/image1.txt)。 - 根据随机抽样或固定规则,将这对文件(图像和标注)移动到
train/或valid/下相应的images和labels文件夹中。 - 确保图像和它的
.txt标注文件始终在同一集合(train 或 valid)中。
- 更新
data.yaml中的train和val路径指向你新创建的train/images和valid/images文件夹。
- 如果你只有一个
步骤 3:设置 Python 和 Ultralytics 环境
- 安装 Python: 确保你安装了较新版本的 Python(推荐 3.8 - 3.11)。
- 创建虚拟环境 (强烈推荐): 这可以避免库版本冲突。
1
2
3
4
5
6
7
8# 使用 venv (Python 内置)
python -m venv yolo_cpu_env
source yolo_cpu_env/bin/activate # Linux/macOS
# yolo_cpu_env\Scripts\activate # Windows
# 或者使用 Conda
# conda create -n yolo_cpu_env python=3.9
# conda activate yolo_cpu_env - 安装 Ultralytics YOLOv8: 在激活的虚拟环境中运行:这会自动安装 PyTorch 的 CPU 版本(因为它检测不到兼容的 GPU/CUDA)以及其他必要的依赖库。
1
pip install ultralytics
步骤 4:配置训练参数
- 选择预训练模型: 为了利用迁移学习并加快(相对而言)收敛速度,你需要从一个预训练模型开始。对于 CPU 训练,强烈建议从小模型开始:
yolov8n.pt(Nano): 最快,占用资源最少,但精度相对较低。CPU 训练的首选起点。yolov8s.pt(Small): 稍大,稍慢,精度稍高。如果yolov8n效果不佳且你的 CPU 尚可承受,可以尝试。- 更大的模型 (
m,l,x) 在 CPU 上训练几乎不可行。 - Ultralytics 会在你第一次使用模型时自动下载
.pt文件。
- 确定训练参数:
model: 你选择的预训练模型,例如yolov8n.pt。data: 指向你准备好的data.yaml文件的路径。epochs: 训练的总轮数。对于 CPU,可以先设置一个较小的值(例如 10-50)来测试流程和观察初步结果,后续再增加。完整训练可能需要 100-300 轮甚至更多,但这在 CPU 上会耗费极长时间。batch: 批处理大小。CPU 训练的关键参数。由于 CPU 计算能力和内存带宽限制,你需要设置一个非常小的值,例如2,4,8。可以从 4 或 8 开始尝试,如果内存不足 (OOM) 或 CPU 占用过高导致系统卡顿,则需要减小。imgsz: 输入图像的尺寸。通常设置为 640。更大的尺寸会显著增加 CPU 计算负担和内存占用。CPU 训练建议保持 640 或更小。device: 必须设置为cpu。device=cpu。workers: 数据加载时使用的 CPU 核心数。可以设置为你 CPU 核心数的一部分,例如2,4。不一定越多越好,过高可能导致 CPU 争用。
步骤 5:执行训练
-
打开终端或命令行。
-
激活你的虚拟环境 (如
source yolo_cpu_env/bin/activate)。 -
导航到你的项目目录 (通常是你存放
data.yaml或打算运行脚本的地方,确保data.yaml中的路径相对于此位置是正确的)。 -
运行训练命令:
1
yolo train model=yolov8n.pt data=/path/to/your/data.yaml epochs=50 batch=4 imgsz=640 device=cpu workers=4
- 请将
/path/to/your/data.yaml替换为你的data.yaml文件的实际路径。 - 根据需要调整
epochs,batch,workers的值。 - 再次强调:请有耐心! 你会看到训练开始,并显示每个 epoch 的进度、损失值等,但这会非常慢。
- 请将
-
或者使用 Python 脚本进行训练: 创建一个 Python 文件(例如
train_cpu.py):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32from ultralytics import YOLO
import torch # 导入 torch 以便检查
if __name__ == '__main__':
# 检查 PyTorch 是否确实在使用 CPU
print(f"PyTorch device: {torch.cuda.is_available() and torch.device('cuda') or torch.device('cpu')}")
# 加载一个预训练模型 (例如 yolov8n.pt)
# 模型文件如果本地没有,首次运行时会自动下载
model = YOLO('yolov8n.pt')
# 开始训练
try:
results = model.train(
data='/path/to/your/data.yaml', # !!替换为你的 data.yaml 路径
epochs=50, # 训练轮数
batch=4, # 批大小 (根据CPU和内存调整)
imgsz=640, # 图像尺寸
device='cpu', # !!指定使用 CPU
workers=4, # 数据加载进程数 (根据CPU核心数调整)
# 其他可选参数:
# project='runs/train_cpu', # 自定义保存结果的项目名
# name='exp_cpu_run1', # 自定义本次运行的名称
# patience=20, # 早停轮数 (如果验证集指标在20轮内没有提升则停止)
# lr0=0.01, # 初始学习率 (通常用默认值)
)
print("训练完成!")
print(f"结果保存在: {results.save_dir}") # results 对象在 v8 中不直接包含 save_dir,需要从 model 或 trainer 获取,或者直接查找 runs/train 目录
except Exception as e:
print(f"训练过程中发生错误: {e}")然后运行脚本:
python train_cpu.py
- GPU版本
1 | # -*- coding: utf-8 -*- |
步骤 6:监控训练和评估结果
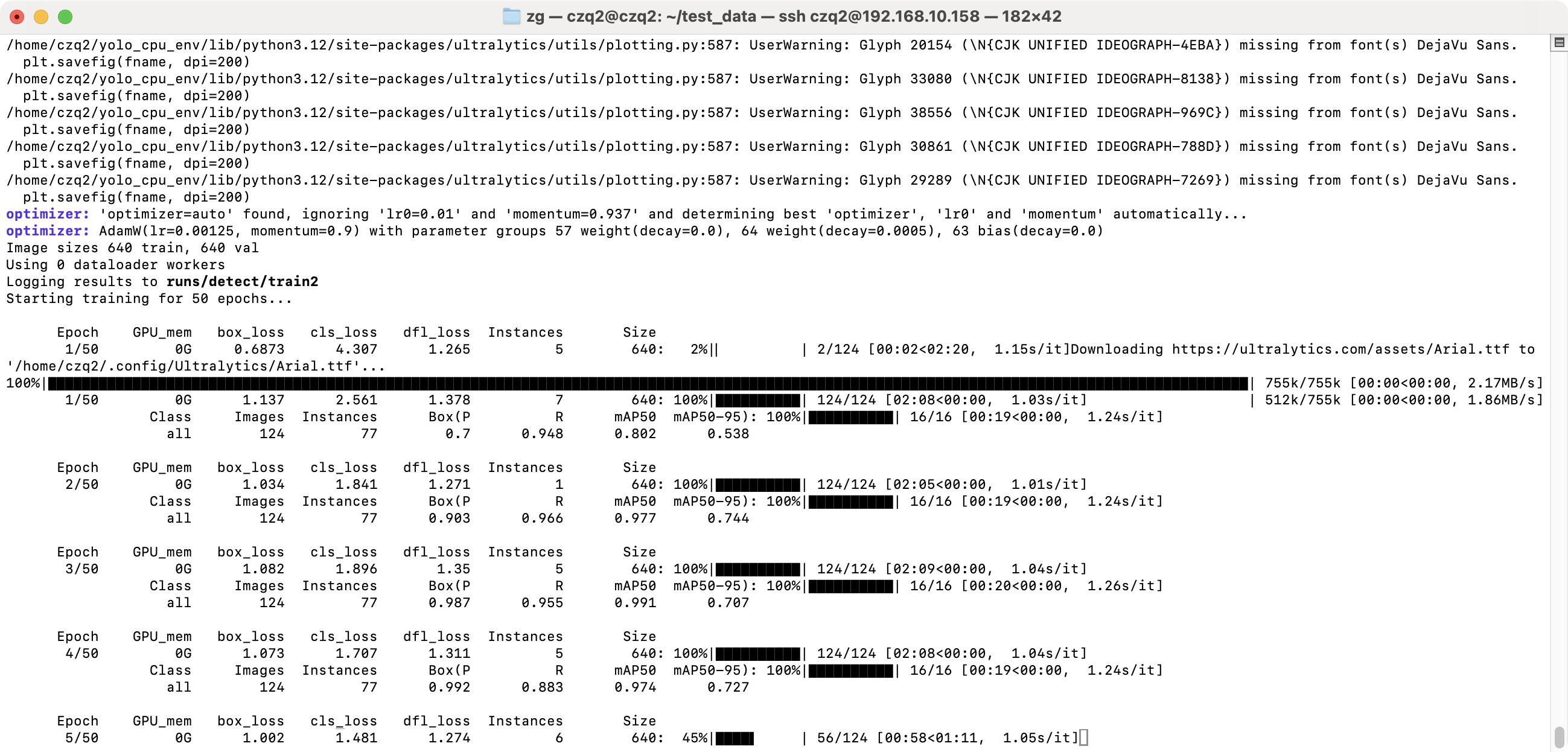
- 观察终端输出: 查看每个 epoch 的进度、损失函数值(box_loss, cls_loss, dfl_loss)是否在下降,以及在验证集上的指标(如 P, R, mAP50, mAP50-95)是否在提升。
- 查找结果: 训练过程和结果默认会保存在
runs/train/exp<N>目录下(例如runs/train/exp,runs/train/exp2等)。里面包含:weights/: 保存的模型权重文件。best.pt是基于验证集指标最佳的模型,last.pt是最后一个 epoch 的模型。best.pt通常是你需要的模型。- 日志文件 (TensorBoard logs)。
- 配置文件副本。
- 验证结果图表和图片(例如
confusion_matrix.png,results.png,val_batch0_pred.jpg等)。
- 验证模型: 训练完成后(或中途),你可以使用
best.pt在验证集上进行评估:1
yolo val model=runs/train/exp<N>/weights/best.pt data=/path/to/your/data.yaml device=cpu
步骤 7:使用训练好的模型
训练完成后,你可以使用 best.pt 文件进行推理(目标检测):
1 | yolo predict model=runs/train/exp<N>/weights/best.pt source=/path/to/image.jpg device=cpu |
或者在 Python 脚本中使用:
1 | from ultralytics import YOLO |
CPU训练的局限性:
- 速度极慢:
- 内存限制: 小心 RAM 耗尽,特别是使用较大的
batch或imgsz时。 - 可行性: 对于非常大的数据集或需要高精度(需要训练更长时间或更大模型)的任务,CPU 训练可能实际上不可行。考虑使用 Google Colab(提供免费 GPU)、Kaggle Kernels 或其他云 GPU 服务可能是更好的选择。
验证数据集获取
获取验证数据集(Validation Set)是训练过程中非常重要的一步,用于评估模型在未见过数据上的表现并调整超参数。当你的数据来自 CVAT 并导出了 YOLO 格式时,有以下几种主要方法来获取或指定验证数据集:
方法一:在 CVAT 中划分并导出 (推荐)
这是最方便、最不容易出错的方法,推荐优先考虑。
- 在 CVAT 中分配子集 (Subset):
- 在你 CVAT 的任务 (Task) 中,你可以将标注好的数据帧或图片分配到不同的子集。默认情况下,所有数据都在
Default或Train子集中。 - 进入你的任务,选择一些帧或图片(例如,随机选择总数据的 10-20%)。
- 点击 “Actions” -> “Change subset”。
- 在弹出的对话框中,选择
Validation作为目标子集,然后确认。 - 这样你就告诉 CVAT,这些选中的数据属于验证集。你也可以同样地分配
Test子集(如果需要)。
- 在你 CVAT 的任务 (Task) 中,你可以将标注好的数据帧或图片分配到不同的子集。默认情况下,所有数据都在
- 导出时包含子集:
- 在你导出任务数据集时,选择
YOLO或YOLO ZIP格式。 - 关键: 在导出选项中,确保你选择了导出所有子集,或者该格式默认就会将不同的子集分开导出。例如,
YOLO ZIP格式通常会自动创建train/,valid/,test/这样的子目录结构。
- 在你导出任务数据集时,选择
- 检查导出的文件:
- 解压下载的 ZIP 文件。
- 检查里面是否已经包含了类似
train/和valid/(或val/) 的文件夹,每个文件夹下又分别有images/和labels/子目录。 - 同时检查
data.yaml文件,它应该已经自动配置好了train:和val:指向这些对应的文件夹(例如train: train/images,val: valid/images)。 - 如果导出文件已经是这种结构,那么你不需要再做任何事情,直接使用这个
data.yaml文件进行训练即可。
方法二:手动划分已导出的数据集
如果你从 CVAT 导出时没有划分小子集,或者导出的格式没有自动区分,那么你只有一个包含所有图像和标签的集合。你需要手动将其划分为训练集和验证集。
- 确定划分比例: 根据你的总数据量,决定一个合适的划分比例。常见的比例是 80% 训练 / 20% 验证,或者 70% / 30%。如果数据量很大,验证集比例可以适当降低。
- 创建目录结构: 在你的数据集根目录下(例如
/home/user/my_dataset),创建如下结构:(可能还需要保留原始的1
2
3
4
5
6
7
8my_dataset/
├── train/
│ ├── images/
│ └── labels/
├── valid/
│ ├── images/
│ └── labels/
└── data.yaml # 你需要创建或修改的文件images/和labels/文件夹,或者直接从那里移动文件)。 - 编写脚本或手动移动文件 (推荐脚本):
- 核心原则: 必须保证同一张图片 (
.jpg,.png等) 和其对应的标注文件 (.txt) 始终被划分到同一个集合 (要么都在train,要么都在valid)。文件名通常是一一对应的(除了扩展名)。 - 脚本方法 (Python 示例):
- 核心原则: 必须保证同一张图片 (
1 | import os |
-
你需要根据你的实际情况修改
dataset_root,source_images_dir,source_labels_dir和train_ratio。 -
这个脚本会将文件移动到新目录。如果你想保留原始文件,可以将
shutil.move改为shutil.copy。 -
手动方法 (仅适用于少量数据): 创建
train和valid子目录,然后手动将图像和对应的.txt文件拖拽到相应的images和labels文件夹中,确保比例大致正确且配对无误。非常容易出错。
- 修改/创建
data.yaml文件:- 在你手动创建了
train/和valid/目录结构后,你需要像下面这样配置data.yaml:1
2
3
4
5
6
7path: /home/user/my_dataset # 数据集根目录
train: train/images # 指向训练图像文件夹
val: valid/images # 指向验证图像文件夹
# test: test/images # 如果有测试集
nc: 3 # 你的类别数量
names: ['car', 'person', 'truck'] # 你的类别名称列表
- 在你手动创建了
方法三:使用 .txt 文件列表 (如果你选择了方案A来创建data.yaml)
如果你是根据 obj.data 文件中的 train = .../train.txt 和 valid = .../valid.txt 来配置 data.yaml 的,那么你需要确保:
train.txt文件确实存在,并且里面列出了所有训练集图像的正确路径(绝对路径或相对于data.yaml中path的路径)。- 你有一个类似的
valid.txt文件,里面列出了所有验证集图像的正确路径。 data.yaml文件中的train:和val:字段正确指向了这两个.txt文件。
如果你只有一个包含所有图像路径的 .txt 文件,你需要像方法二中划分文件一样,将这个 .txt 文件也划分成两个文件:train.txt 和 valid.txt,确保划分比例合适。
总结:
- 最佳方式: 在 CVAT 中就使用 “Subset” 功能区分好训练集和验证集,然后导出
YOLO ZIP格式,通常data.yaml就配置好了。 - 次佳方式: 如果导出的数据未划分,使用脚本(如上例)将其自动划分为
train/和valid/目录结构,然后相应地配置data.yaml指向这些目录。 - 如果依赖
.txt列表: 确保你有分别列出训练图像和验证图像路径的train.txt和valid.txt文件,并在data.yaml中正确引用它们。
无论哪种方法,最终目标都是要有一个明确区分的训练数据集和一个验证数据集,并且 data.yaml 文件能够准确地告诉 YOLOv8 框架去哪里找到它们。
训练结果
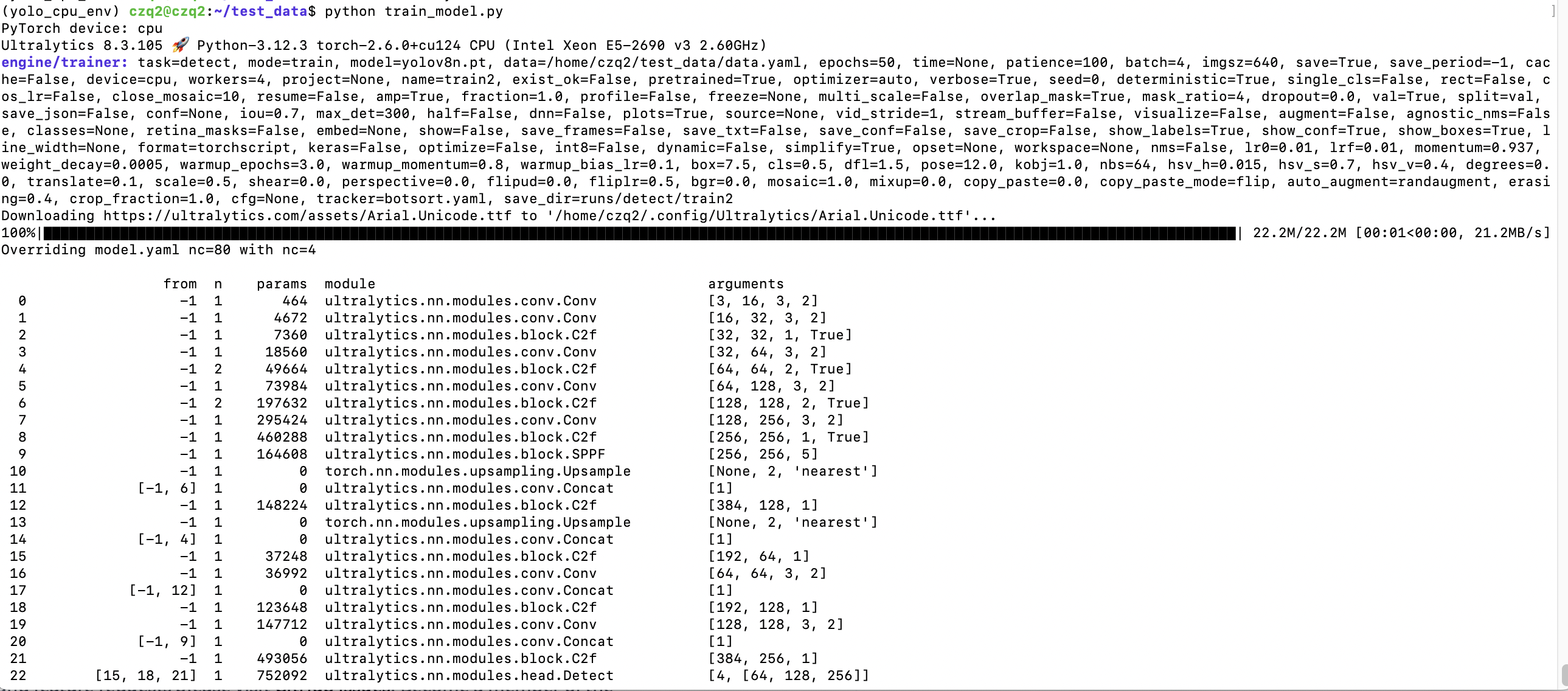
1 | python train_model.py |
-
参数定义
-
我们来详细解释一下 YOLOv8 训练过程中这一行输出的含义:
1 | Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size |
和
1 | Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 16/16 [00:19<00:00, 1.23s/it] |
第一部分:训练进度和损失 (Training Progress and Loss)
1 | Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size |
Epoch:12/50- 表示当前训练正在进行第 12 轮 (epoch),总共计划训练 50 轮。一个 epoch 指的是模型完整地看过一遍所有的训练数据。
GPU_mem:0G- 显示当前 GPU 显存 (VRAM) 的使用量。这里显示
0G非常奇怪,尤其是如果你指定了使用 GPU 进行训练。- 可能的原因 1 (最可能): 训练实际上是在 CPU 上运行的,即使你可能指定了
device=0或device='cuda'。这通常发生在 PyTorch 无法正确检测或使用你的 GPU 时(驱动、CUDA、cuDNN 或 PyTorch 版本问题)。你需要回过头去验证你的 GPU 环境是否配置正确,以及 PyTorch 是否能真正使用 GPU (torch.cuda.is_available()必须为True)。 - 可能的原因 2 (不太可能): 你的模型和批次大小非常小,以至于显存占用可以忽略不计(对于 YOLOv8 尤其是
x模型和batch=4来说几乎不可能)。 - 可能的原因 3 (极少): 监控显存的工具或接口暂时失效。
- 可能的原因 1 (最可能): 训练实际上是在 CPU 上运行的,即使你可能指定了
- 正常的 GPU 训练 应该会显示一个非零的显存使用值,例如
5.8G,10.2G等,具体取决于模型大小、批大小和图像尺寸。
- 显示当前 GPU 显存 (VRAM) 的使用量。这里显示
box_loss:0.8517- 边界框损失 (Bounding Box Loss)。这个值衡量的是模型预测的边界框位置/大小与真实边界框之间的差异。值越低越好。
cls_loss:0.8027- 分类损失 (Classification Loss)。这个值衡量的是模型预测的物体类别与真实类别之间的差异。值越低越好。
dfl_loss:1.157- 分布焦点损失 (Distribution Focal Loss)。这是 YOLOv8(尤其是 v8 及更新版本)引入的一种用于边界框回归的损失,它将边界框的连续坐标回归问题转化为离散的概率分布预测问题,有助于提高定位精度。值越低越好。
Instances:4- 当前正在处理的这个批次 (batch) 中包含的目标实例 (objects) 的数量。这里是 4 个。注意这不是批大小(batch size,即图像数量)。
Size:640- 训练时输入模型的图像尺寸 (通常是 height 和 width 都设为这个值,即 640x640)。
100%|██████████| 124/124 [02:08<00:00, 1.04s/it]:- 这是一个进度条,显示当前 epoch 内训练数据的处理进度。
100%: 表示当前 epoch 的训练数据已全部处理完毕。124/124: 表示当前 epoch 共处理了 124 个批次 (batches),现在已经完成了第 124 个批次。 (总批次数 = 总训练图像数 / batch_size)[02:08<00:00]: 当前 epoch 已用时 2 分 8 秒,预计剩余时间 0 秒。1.04s/it]: 处理一个批次 (iteration) 平均需要 1.04 秒。这个速度对于 GPU 来说相当慢,进一步印证了可能是在 CPU 上运行。GPU 训练通常是ms/it(毫秒每迭代)。
第二部分:验证结果评估 (Validation Results Evaluation)
这部分通常在每个 epoch 的训练结束后(或者根据设置的频率)运行,使用验证集 (Validation Set) 来评估当前模型的性能。
1 | Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 16/16 [00:19<00:00, 1.23s/it] |
Class:all- 表示这一行显示的是所有类别的平均性能指标。如果你的数据集有多个类别,通常还会在这里或下面几行列出每个单独类别的指标。
Images:124- 你的验证集中包含 124 张图像。
Instances:77- 你的验证集中所有图像总共包含 77 个已标注的目标实例。
Box(P R mAP50 mAP50-95): 这是目标检测任务最核心的评估指标:P(Precision / 精确率):1- 指模型预测为正例(检测到物体)的样本中,真正是正例的比例。计算公式:
TP / (TP + FP)(真阳性 / (真阳性 + 假阳性))。 - 值为
1意味着所有模型检测到的物体都是正确的(没有误报)。这个值通常在 IoU (Intersection over Union) 阈值为 0.5 时计算,并且可能是针对某个最优置信度阈值得出的。
- 指模型预测为正例(检测到物体)的样本中,真正是正例的比例。计算公式:
R(Recall / 召回率):0.999- 指所有真实的正例(所有实际存在的物体)中,被模型成功预测出来的比例。计算公式:
TP / (TP + FN)(真阳性 / (真阳性 + 假阴性))。 - 值
0.999意味着模型找回了验证集中几乎所有(99.9%)的真实物体(漏报非常少)。这个值通常也是在 IoU 阈值为 0.5 时计算,并且可能是针对某个最优置信度阈值得出的。
- 指所有真实的正例(所有实际存在的物体)中,被模型成功预测出来的比例。计算公式:
mAP50(mean Average Precision @ IoU=0.5):0.995- IoU (交并比) 阈值设置为 0.5 时,计算所有类别的平均精度 (Average Precision, AP),然后对所有类别求平均值 (mean AP)。AP 是综合了精确率和召回率的指标,它衡量的是 PR 曲线下的面积。
0.995是一个非常高的值,表示在 IoU=0.5 的标准下,模型性能非常好。
mAP50-95(mean Average Precision @ IoU=0.5:0.95):0.853- 这是更严格、也是 COCO 数据集竞赛等场景中更常用的标准。它计算了 IoU 阈值从 0.5 到 0.95、步长为 0.05 的一系列 IoU 值下的 mAP,然后对这些 mAP 求平均。
- 这个指标对检测框的定位精度要求更高。
0.853(即 85.3%) 是一个相当不错的性能,表明模型不仅能检测到物体,而且定位也比较准确。
100%|██████████| 16/16 [00:19<00:00, 1.23s/it]:- 这是验证过程的进度条。
16/16: 表示验证集被分成了 16 个批次进行处理,现在已经处理完了。 (验证批次数 = 总验证图像数 / 验证批大小,验证批大小可能与训练批大小不同)。[00:19<00:00]: 整个验证过程用时 19 秒。1.23s/it]: 处理一个验证批次平均需要 1.23 秒。这个速度同样说明很可能是在 CPU 上运行。

