python 使用tesseract实现实时监控桌面
技术介绍
Tesseract是一个 由HP实验室开发 由Google维护的开源的光学字符识别(OCR)引擎,可以在 Apache 2.0 许可下获得。它可以直接使用,或者(对于程序员)使用 API 从图像中提取输入,包括手写的或打印的文本。与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练语言,提高图像转换文本的能力
下载地址
1
| https://digi.bib.uni-mannheim.de/tesseract/
|
第三方库安装
1
2
3
| pip install pytesseract -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pillow -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pywin32 PyAutoGUI pygetwindow loguru
|
demo
测试代码
1
2
3
4
5
6
7
8
9
10
11
|
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
img_path = "../chi.PNG"
result = pytesseract.image_to_string(image=img_path, lang="chi_sim", config="--psm 1")
print(result)
|
案例
实现思路
通过pillow动态抓取屏幕截图,tesseract动态识别图片内容,过滤所需信息,即可实现对桌面(主屏)的动态监控
demo 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
| import pygetwindow as gw
import pyautogui
import time
from loguru import logger
from run import constants
import pytesseract
from PIL import ImageGrab, Image
import os
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
@logger.catch
def ocr_screenshot():
"""
:return:
"""
screenshot = ImageGrab.grab()
temp_file = "screenshot.png"
screenshot.save(temp_file)
text = pytesseract.image_to_string(Image.open(temp_file))
os.remove(temp_file)
return text
@logger.catch
def process_msg(process_result):
"""
:param process_result:
:return:
"""
result_list = []
for version_msg in version_pre_list:
complete_str = success_result_pre + ecu_head + version_msg
ret = extract_after_string(process_result, complete_str)
ret = ret.replace("S", "5").replace("o", "0").replace("l", "1")
if ret != "":
logger.success(f"find version msg: {ret}")
result_list.append(ret)
return result_list
@logger.catch
def extract_after_string(source_str, search_str):
"""
提取source_str中search_str之后的内容,直到遇到换行符为止。
:param source_str: 原始字符串
:param search_str: 要搜索的子字符串
:return: search_str之后的内容,直到换行符为止
"""
index = source_str.find(search_str)
if index != -1:
end_index = source_str.find('\n', index + len(search_str))
if end_index != -1:
return source_str[index + len(search_str):end_index]
else:
return source_str[index + len(search_str):]
else:
return ""
@logger.catch
def detect_status_dsa(ocr_result):
"""
:param ocr_result:
:return:
"""
try:
if test_pre in ocr_result:
if fail_msg_head in ocr_result:
fail_result = extract_after_string(ocr_result, fail_msg_head)
logger.warning(f"catch error: {fail_result}")
elif success_result_pre in ocr_result:
process_msg(ocr_result)
else:
no_result = extract_after_string(ocr_result, test_pre)
logger.debug(f"current not found result: {no_result}")
except Exception as e:
logger.error(f"Unknown error, detail:{e}]")
return []
if __name__ == '__main__':
constants.detect_dsa_flag = True
while constants.detect_dsa_flag:
time.sleep(1 / 10)
result = ocr_screenshot()
detect_ret_list = detect_status_dsa(result)
if not detect_ret_list:
logger.warning("no result, start next loop detect.")
continue
else:
constants.detect_dsa_version_msg = "\n".join(detect_ret_list)
logger.debug(f"result: {constants.detect_dsa_version_msg}")
|
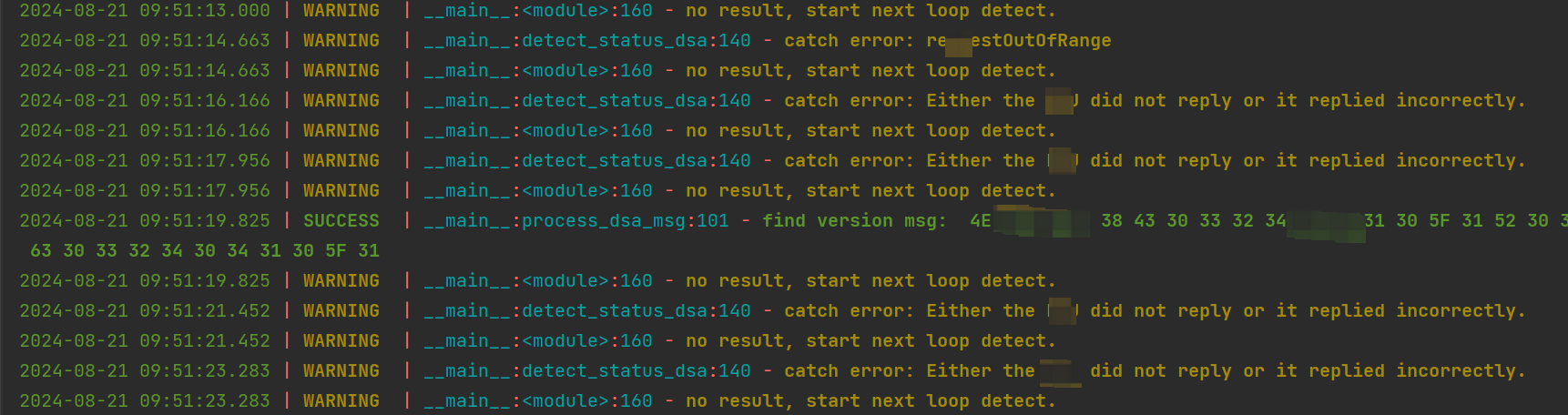
实现效果
- 如图
about me 个人微信

wechat offical 微信公众号


